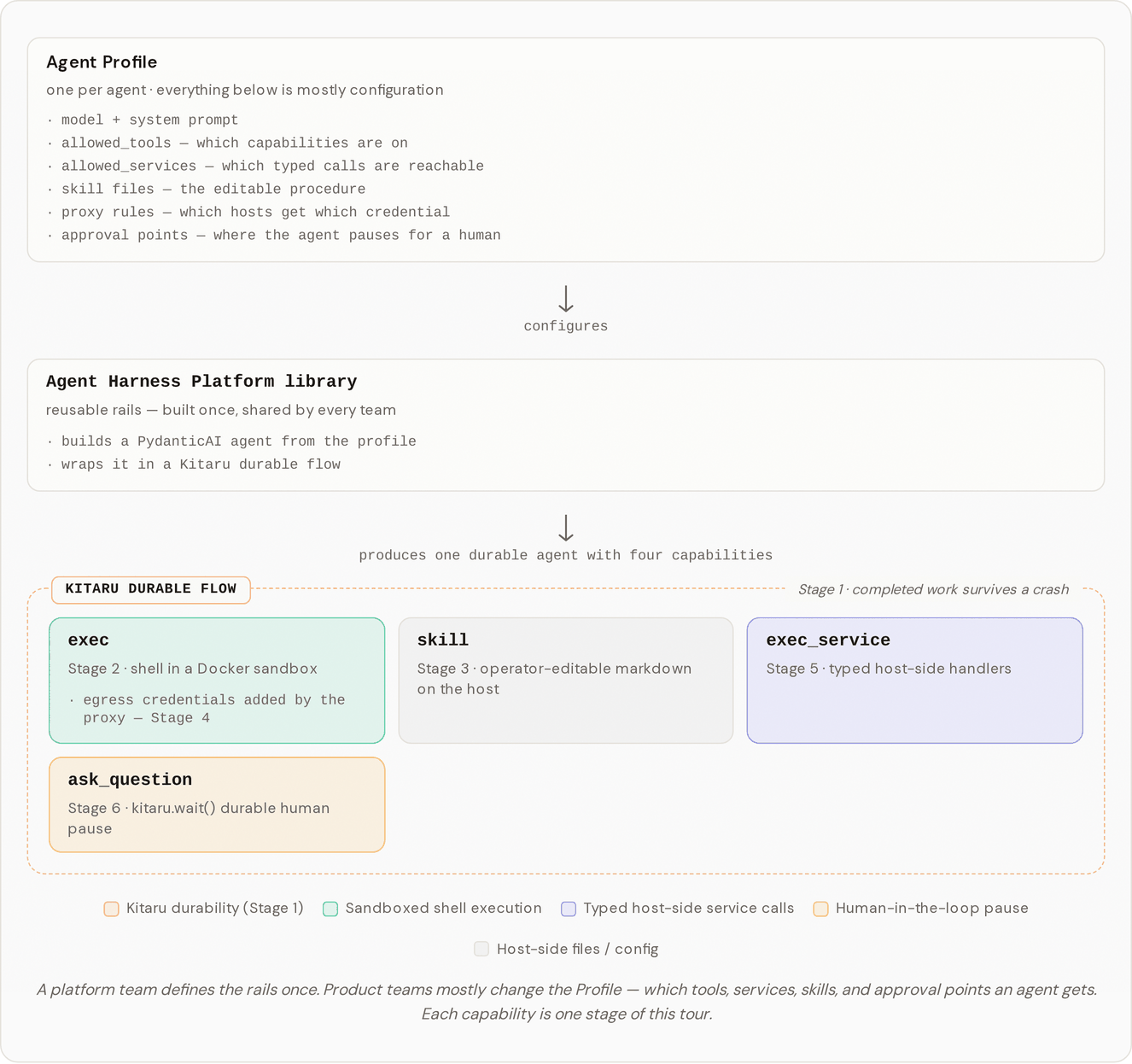
| Sandboxed command execution | Put shell commands in a Docker sandbox with its own filesystem and network namespace, rather than running agent-generated commands on the host. | /pages/Pg2Qt5UDJIBmVQ1olxjS |
| Operator-editable procedures | Move repeatable agent instructions into skill markdown files, so teams can change procedures without burying every rule in the system prompt. | /pages/t2JZ39WPu66cDYTUd7nC |
| Credential isolation | Keep secrets out of the worker. A separate proxy process holds credentials and adds auth headers for approved internal calls. | /pages/WnTuBKPRQQs6L4xSgbKU |
| Typed service boundaries | Route structured service requests through a typed dispatcher, so the platform can decide exactly which internal actions an agent may call. | /pages/FTShFcd4zW2cljRHs4Ki |
| Durable human approval | Pause a run with kitaru.wait(), ask a human for a decision, and resume the same flow after the answer arrives. | /pages/bnKRh2VYepJPgyfJYFfD |