> For the complete documentation index, see [llms.txt](https://docs.zenml.io/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.zenml.io/kitaru/core-concepts/wait-and-input.md).
# Wait, Input, and Resume
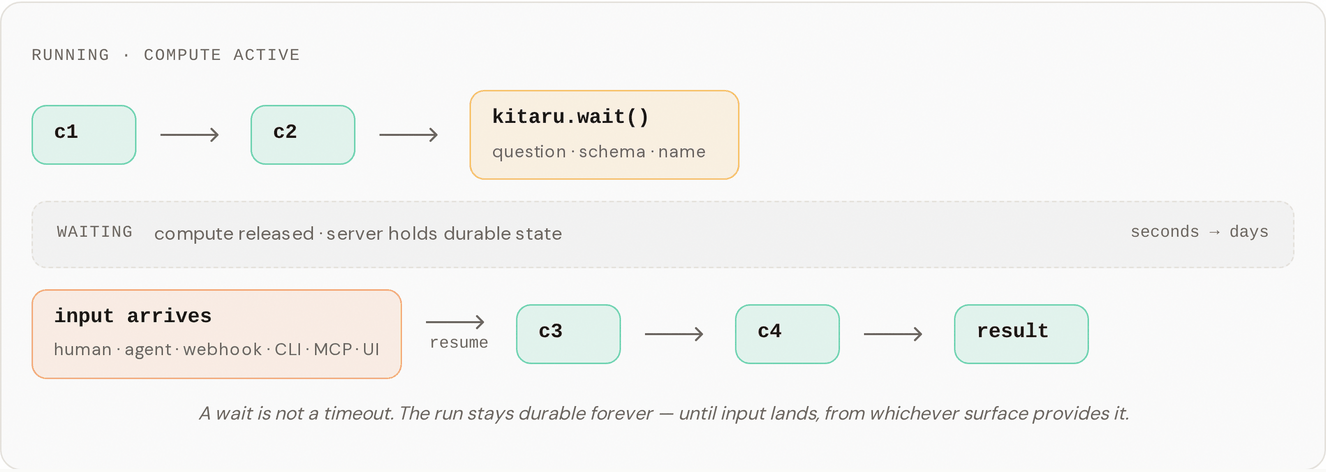
`kitaru.wait()` suspends a running flow until a human, another agent, or an external system provides input. It exists because durable runs let a flow stop and resume without losing state: when execution hits a wait, the server holds the run's checkpoints and the runner can release compute. The execution resumes seconds, hours, or months later when input lands, picking up at the exact wait point with the same state and artifacts. In non-interactive runs the runner polls for input up to its `timeout` (default 600 seconds), then exits.
## The wait/resume timeline
The server holds the run's durable state while compute is idle. When input lands, the runner picks up at the exact point the wait left off, with the same checkpoint state and artifacts.
## Full example
```python
import kitaru
from kitaru import checkpoint, flow
@checkpoint
def research(topic: str) -> str:
return kitaru.llm(f"Summarize the latest developments in {topic}.")
@checkpoint
def write_report(summary: str) -> str:
return kitaru.llm(f"Write a short report based on:\n\n{summary}")
@flow
def research_agent(topic: str) -> str:
summary = research(topic)
summary_text = summary.load()
approved = kitaru.wait(
name="approve_summary",
question=f"The agent produced this summary:\n\n{summary_text}\n\nApprove?",
schema=bool,
)
if not approved:
return "Report rejected by reviewer."
return write_report(summary)
if __name__ == "__main__":
research_agent.run(topic="durable execution for AI agents")
```
The flow calls `.load()` only for the human-facing wait question. The original `summary` checkpoint output is still passed to `write_report(summary)` so Kitaru keeps the durable data flow between checkpoints intact. See [In flow bodies](/kitaru/guides/artifacts.md#in-flow-bodies) for more on when to materialize checkpoint outputs in orchestration code.
## Where wait() can be called
`kitaru.wait()` must be called at flow scope. In practice, that means inside the `@flow` function body, before or after checkpoint calls, not inside a `@checkpoint` function.
A wait pauses the whole run. If `wait()` pauses from inside a checkpoint, the run can stop before that checkpoint call has completed cleanly. That can leave things in a confusing state where the run is waiting for input, but the checkpoint call is marked failed. To avoid that state, Kitaru raises this error immediately:
```
wait() cannot run inside a @checkpoint. Move the wait to flow scope, before or after checkpoint calls.
```
The companion rule is that `wait()` needs a running flow. If you call it outside a `@flow`, Kitaru raises `wait() can only run inside a @flow.`
If you need input halfway through a larger operation, split the operation into two checkpoints and put the wait between them:
```python
@checkpoint
def draft_report(topic: str) -> str:
return kitaru.llm(f"Draft a report about {topic}.")
@checkpoint
def revise_report(draft: str, reviewer_note: str) -> str:
return kitaru.llm(f"Revise this report using {reviewer_note}:\n\n{draft}")
@flow
def reviewed_report(topic: str) -> str:
draft = draft_report(topic)
draft_text = draft.load()
reviewer_note = kitaru.wait(
name="review_draft",
question=f"Review this draft:\n\n{draft_text}",
schema=str,
)
return revise_report(draft, reviewer_note)
```
The `draft.load()` call is only there so the reviewer can see the draft text in the wait question. The original `draft` checkpoint output still flows into the next checkpoint.
When execution reaches `kitaru.wait()`:
1. The flow suspends and the execution moves to `waiting` status
2. The question, schema, and metadata are recorded on the server
3. The runner polls for input up to its `timeout`. If input arrives first, the flow continues in the same process. If the timeout elapses first, the runner exits and compute is released; input can still land later, and `kitaru executions resume` picks up from exactly this point.
## Providing input
### From the CLI
```bash
# Provide the answer directly (auto-detects the pending wait)
kitaru executions input --value true
# Interactive mode — shows the question and schema, prompts for input
kitaru executions input --interactive
# Sweep all waiting executions interactively
kitaru executions input --interactive
```
### From Python
```python
client = kitaru.KitaruClient()
client.executions.input(
"",
wait="approve_summary",
value=True,
)
```
### From the UI
The UI shows all executions in `waiting` status with the question and expected schema. You can provide input directly from the UI.
## Before timeout vs. after timeout
This is an important distinction. The `timeout` parameter (default: 600 seconds) controls how long the **runner process** keeps polling for input before it exits:
### Input arrives before timeout
The runner is still alive and polling. When you provide input, the flow continues immediately in the same process. No extra step needed.
### Input arrives after timeout
The runner has already exited and released compute. Your input is recorded on the server, but there is no running process to pick it up. You need to explicitly resume the execution:
{% tabs %}
{% tab title="CLI" %}
```bash
# Step 1: provide the input (auto-detects the pending wait)
kitaru executions input --value true
# Step 2: resume the execution (starts a new runner)
kitaru executions resume
```
{% endtab %}
{% tab title="Python" %}
```python
client = kitaru.KitaruClient()
# Step 1: provide the input
client.executions.input("", wait="approve_summary", value=True)
# Step 2: resume the execution
client.executions.resume("")
```
{% endtab %}
{% endtabs %}
{% hint style="info" %}
The `timeout` is not a deadline on the wait itself — the wait never expires. It only controls how long the runner process stays alive polling for a response. After timeout, the input can still be provided at any time.
{% endhint %}
## Wait parameters
| Parameter | Default | What it does |
| ---------- | -------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `name` | Auto-generated | Identifier for this wait point (used when providing input) |
| `question` | `None` | Human-readable prompt shown in the CLI, UI, and MCP |
| `schema` | `None` | Expected type of the input. When `None`, the wait acts as a continue/abort gate returning `None`. Pass a type (e.g. `bool`, a Pydantic model) to validate input against it. |
| `timeout` | `600` | Seconds the runner polls before exiting (not a wait expiration) |
| `metadata` | `None` | Additional key-value data attached to the wait record |
## Next steps
* [Wait, Input, and Resume guide](/kitaru/guides/wait-and-resume.md) — detailed patterns including local interactive mode and abort
* [Execution Management](/kitaru/guides/execution-management.md) — inspect, replay, and manage executions
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://docs.zenml.io/kitaru/core-concepts/wait-and-input.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.