> For the complete documentation index, see [llms.txt](https://docs.zenml.io/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.zenml.io/kitaru/core-concepts/checkpoints.md).
# Checkpoints
A **checkpoint** is a unit of work inside a flow whose inputs and output are recorded durably. Checkpoints are the recorded boundaries that make two things possible: **resume** a failed run from where it stopped, and **faithfully replay** a real run so you can change one thing and trust the diff. In ZenML terms, a checkpoint is like a step; a Kitaru flow is a dynamic pipeline of them.
A checkpoint is also the **contract between the runner and the** [**execution target**](/kitaru/core-concepts/how-it-works.md): the runner owns durable control flow (order, retry, replay, resume, wait), the execution target (inline, isolated container, sandbox, external tool) does the work, and the checkpoint is the recorded boundary they agree on. That is why a checkpoint failure is never just a crash — it is persisted context the runner, an agent loop, or a human can retry, replay, or feed back into the flow. See [How it works](/kitaru/core-concepts/how-it-works.md) for the full model.
## Checkpoints are replay boundaries
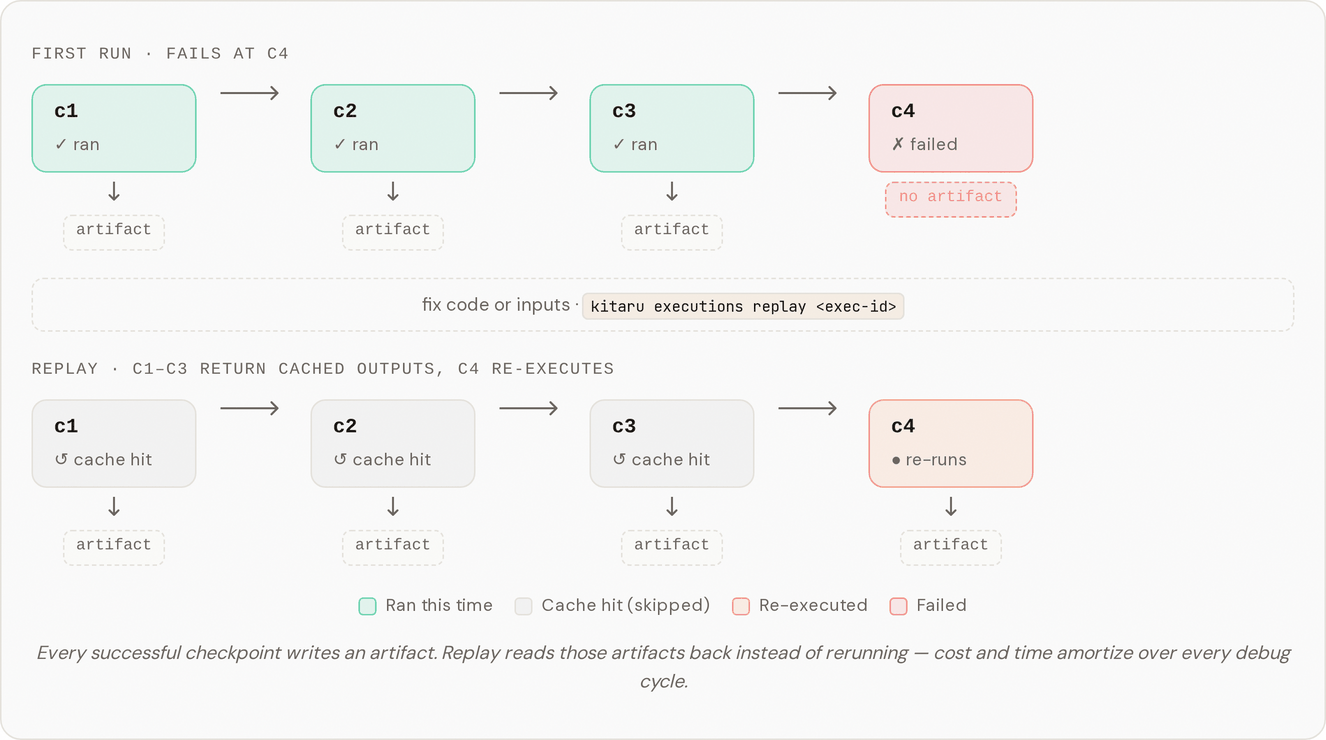
Every checkpoint is a boundary the runner remembers. On the first run, each checkpoint's inputs and output are computed and stored. This recording is what makes replay faithful: when you replay an execution, completed checkpoints return their persisted outputs and execution only re-enters the first checkpoint affected by your change. Everything you didn't touch reproduces exactly, so a rerun with no change is a faithful baseline and any difference you see is your change — not replay noise.
This is the foundation of the **run, replay, improve** loop: because checkpoints record the real run, you can replay it with one input changed (a different model or prompt via `flow.replay(exec_id, at="", flow_overrides={...})`) and diff the two runs. See [Replay and overrides](/kitaru/guides/replay-and-overrides.md).
{% hint style="info" %}
Replay now has three override levels. `flow_overrides` changes top-level flow inputs. `checkpoint_overrides` targets every recorded call with a checkpoint name. `invocation_overrides` targets one recorded checkpoint, tool, or model call by invocation ID or call ID.
{% endhint %}
## Defining a checkpoint
Decorate work functions with `@checkpoint`:
```python
from kitaru import checkpoint
@checkpoint
def fetch_data(url: str) -> str:
return requests.get(url).text
@checkpoint
def process_data(data: str) -> str:
return data.upper()
```
Checkpoints are reusable — define them once and call them from any flow.
## Composing checkpoints in a flow
Call checkpoints from inside a `@flow` to build your workflow:
```python
from kitaru import flow
@flow
def my_agent(url: str) -> str:
data = fetch_data(url)
result = process_data(data)
return result
```
Checkpoints execute sequentially by default. The return value of one checkpoint can be passed directly as input to the next — standard Python data flow.
## Concurrent execution
For independent work that can run in parallel, use `.submit()`:
```python
from kitaru import flow
@flow
def parallel_agent(urls: list[str]) -> list[str]:
futures = [fetch_data.submit(url) for url in urls]
return [f.result() for f in futures]
```
`.submit()` returns a future-like object. Call `.result()` on it to get the checkpoint's return value. This is the primary fan-out pattern in Kitaru.
{% hint style="info" %}
The object returned by `.submit()` is a runtime future — use `.result()` to collect the value. You can submit multiple checkpoints and collect their results later for fan-out / fan-in patterns.
{% endhint %}
### Additional concurrent helpers
Kitaru also provides `.map()` and `.product()` for batch concurrent execution:
```python
# .map() — apply checkpoint to each element of an iterable
results = fetch_data.map(["url1", "url2", "url3"])
# .product() — apply checkpoint to the cartesian product of inputs
results = my_checkpoint.product(["a", "b"], [1, 2])
```
These are convenience wrappers over concurrent submission. See the [API reference](https://sdkdocs.kitaru.ai) for detailed signatures.
## Decorator options
```python
from kitaru import checkpoint
@checkpoint(retries=3, type="llm_call")
def call_model(prompt: str) -> str:
...
```
| Option | Default | What it controls |
| --------- | ------- | -------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `retries` | `0` | Automatic retries on checkpoint failure |
| `cache` | `True` | Reuse the persisted output from a previous run when inputs and code match. Set `False` to disable on this checkpoint (overrides the flow-level default). |
| `type` | `None` | A label for UI visualization (e.g. `"llm_call"`, `"tool_call"`) |
| `runtime` | `None` | Execution runtime: `"inline"` or `"isolated"` (see below) |
Like flow options, `retries` must be non-negative.
### Isolated runtime
By default, checkpoints run **inline** — in the same process/pod as the runner. This is the right default for most orchestration. For checkpoints that run untrusted code, need a different image or resources, or must be strongly isolated from the rest of the run, set `runtime="isolated"` and the runner will place the checkpoint on a separate container/job on the configured stack (Kubernetes, Vertex AI, SageMaker, AzureML). Locally it falls back to inline so dev loops stay fast.
```python
@checkpoint(runtime="isolated")
def heavy_computation(data: str) -> str:
...
```
This applies to every execution of the checkpoint, whether called directly or submitted concurrently with `.submit()`:
```python
@flow
def parallel_agent(items: list[str]) -> list[str]:
# Each submission runs in its own container when runtime="isolated"
futures = [heavy_computation.submit(item) for item in items]
return [f.result() for f in futures]
```
{% hint style="info" %}
`runtime` controls **where** a checkpoint runs (same process vs. separate container). `.submit()` controls **when** — it enables concurrency. The two are independent: you can use `.submit()` without isolation, or isolation without `.submit()`.
{% endhint %}
{% hint style="warning" %}
If the active orchestrator does not support isolated steps, the runtime is silently downgraded to inline with a warning. Local stacks always run inline.
{% endhint %}
### Running a command in the active sandbox
If your active stack has a sandbox component, checkpoint code can ask Kitaru to run one command inside that sandbox:
```python
from kitaru import checkpoint, flow, run_sandbox_command
@checkpoint
def inspect_python() -> str:
result = run_sandbox_command(
["python", "-c", "import sys; print(sys.version)"],
max_chars=20_000,
)
if result.exit_code != 0:
raise RuntimeError(result.stderr)
return result.stdout
@flow
def sandbox_probe() -> str:
return inspect_python()
```
The helper creates a fresh sandbox session, runs the command, collects stdout and stderr, then cleans up the session. Non-zero exit codes do **not** raise by themselves. The story is: the command runs, the process exits with `2`, Kitaru still returns the captured output, and your code decides whether `2` means "expected tool result" or "stop the flow".
`SandboxCommandResult` includes:
* `stdout`, `stderr`, and `exit_code`
* `stdout_truncated` and `stderr_truncated`, so you can tell when output hit the `max_chars` limit
* `cleanup_succeeded` and `cleanup_error`, so providers that cannot destroy a session can still return the command result while telling you cleanup was only partially completed
This is a direct SDK helper. Agent adapters do not automatically route their tool calls through it unless that adapter documents such behavior.
When retries are enabled, Kitaru records each failed attempt before the final checkpoint outcome. You can inspect this history through `KitaruClient().executions.get(exec_id).checkpoints[*].attempts`.
## Error handling and retries
When a checkpoint raises an unhandled exception, the flow stops immediately and the execution is marked as **failed**. No subsequent checkpoints run.
### Automatic retries
The `retries` parameter on `@checkpoint` tells Kitaru to re-run the checkpoint automatically before giving up:
```python
@checkpoint(retries=3)
def call_model(prompt: str) -> str:
return client.chat(prompt) # retried up to 3 times on failure
```
Each failed attempt is recorded, so you can inspect the full retry history through the execution's checkpoint attempts. If the checkpoint still fails after all retries, the flow fails.
For retrying the **entire flow** (not just a single checkpoint), see the [`retries` option on flows](/kitaru/core-concepts/flows.md#runtime-options).
### Resuming after failure
When a flow fails, you don't need to re-run everything from scratch. Use [replay](/kitaru/guides/replay-and-overrides.md) to re-execute from the point of failure: checkpoints that already succeeded return their recorded results, and execution picks up at the first incomplete checkpoint. This is the same machinery as faithful replay above — resume is replay with no input change.
## Return values
Checkpoint return values must be serializable — Kitaru persists them so they can be reused in future executions. Prefer:
* Built-in Python types (`str`, `int`, `float`, `bool`, `list`, `dict`)
* Pydantic models
* JSON-compatible data structures
## Rules to know
Kitaru enforces several guardrails in the current release:
* **Checkpoints only work inside a flow.** Calling a checkpoint outside a `@flow` raises `KitaruContextError`.
* **No nested checkpoints.** Calling one checkpoint from inside another is not supported and raises `KitaruContextError`.
* **`.submit()` requires a running flow.** Concurrent submission is only available during flow execution, not during flow compilation.
* **`.map()` and `.product()` follow the same rules as `.submit()`** — they require a running flow context.
```python
from kitaru import checkpoint
# This raises KitaruContextError — checkpoint called outside a flow
fetch_data("https://example.com")
# This also raises KitaruContextError — nested checkpoint
@checkpoint
def outer():
return inner() # inner is also a checkpoint — not allowed
```
## Next steps
* Add structured metadata to your checkpoints with [Logging and Metadata](/kitaru/core-concepts/logging.md)
* Understand how results and errors surface in [Flows](/kitaru/core-concepts/flows.md#how-errors-surface)
* See the full API in the [Checkpoint Reference](https://sdkdocs.kitaru.ai)
## Related blog posts
* [Why agents need durable execution](https://kitaru.ai/blog/why-agents-need-durable-execution)
* [No journal replay](https://kitaru.ai/blog/no-journal-replay)
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://docs.zenml.io/kitaru/core-concepts/checkpoints.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.